
45 The Genetic Code
To summarize what we know to this point, the cellular process of transcription generates messenger RNA (mRNA), a mobile molecular copy of one or more genes with an alphabet of A, C, G, and uracil (U). Translation of the mRNA template converts nucleotide-based genetic information into a protein product. Protein sequences consist of 20 commonly occurring amino acids; therefore, it can be said that the protein alphabet consists of 20 letters. Each amino acid is defined by a three-nucleotide sequence called the triplet codon. The relationship between a nucleotide codon and its corresponding amino acid is called the genetic code.
Given the different numbers of “letters” in the mRNA and protein “alphabets,” combinations of nucleotides corresponded to single amino acids. Using a three-nucleotide code means that there are a total of 64 (4 × 4 × 4) possible combinations; therefore, a given amino acid is encoded by more than one nucleotide triplet (Figure 8).
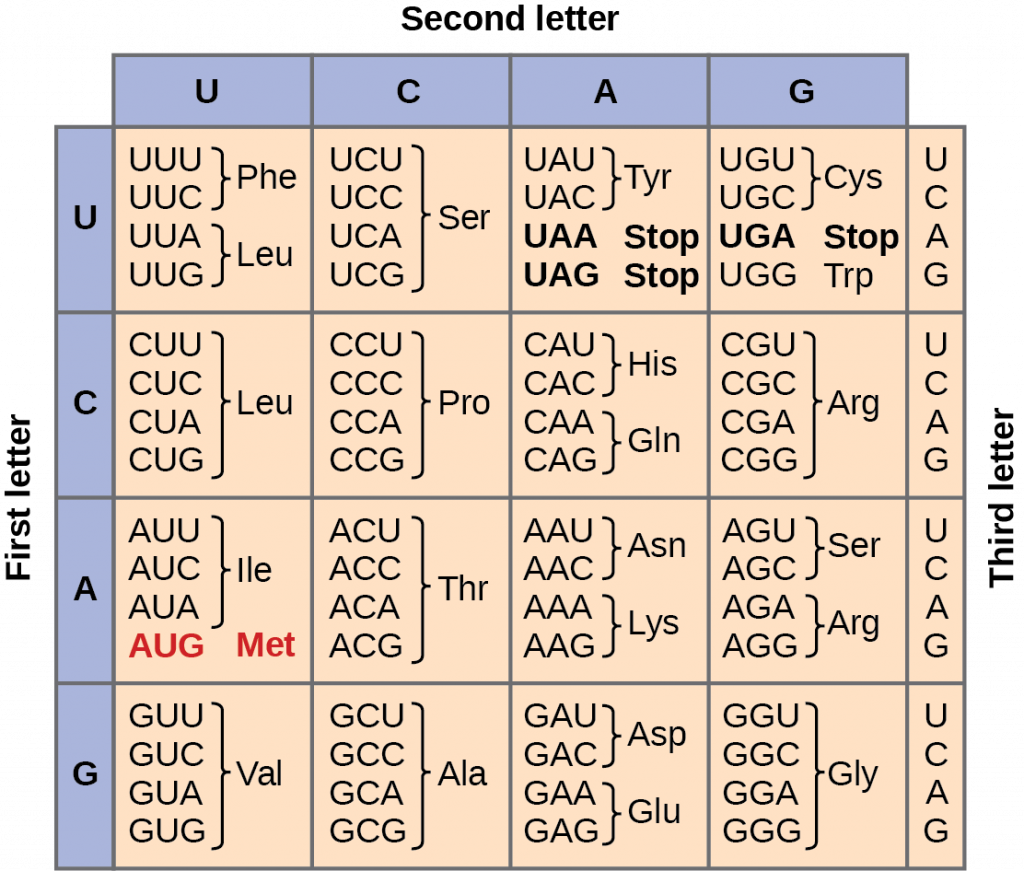
Three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery. These triplets are called stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5′ end of the mRNA. The genetic code is universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all life on Earth shares a common origin.
Using the Codon Table
Codon tables, such as the one in Figure 8, give the amino acids that are coded for by mRNA codons, not DNA codons. If you are given a DNA sequence, you must first transcribe it to produce the mRNA, then you can translate it into an amino acid sequence using the codon table.
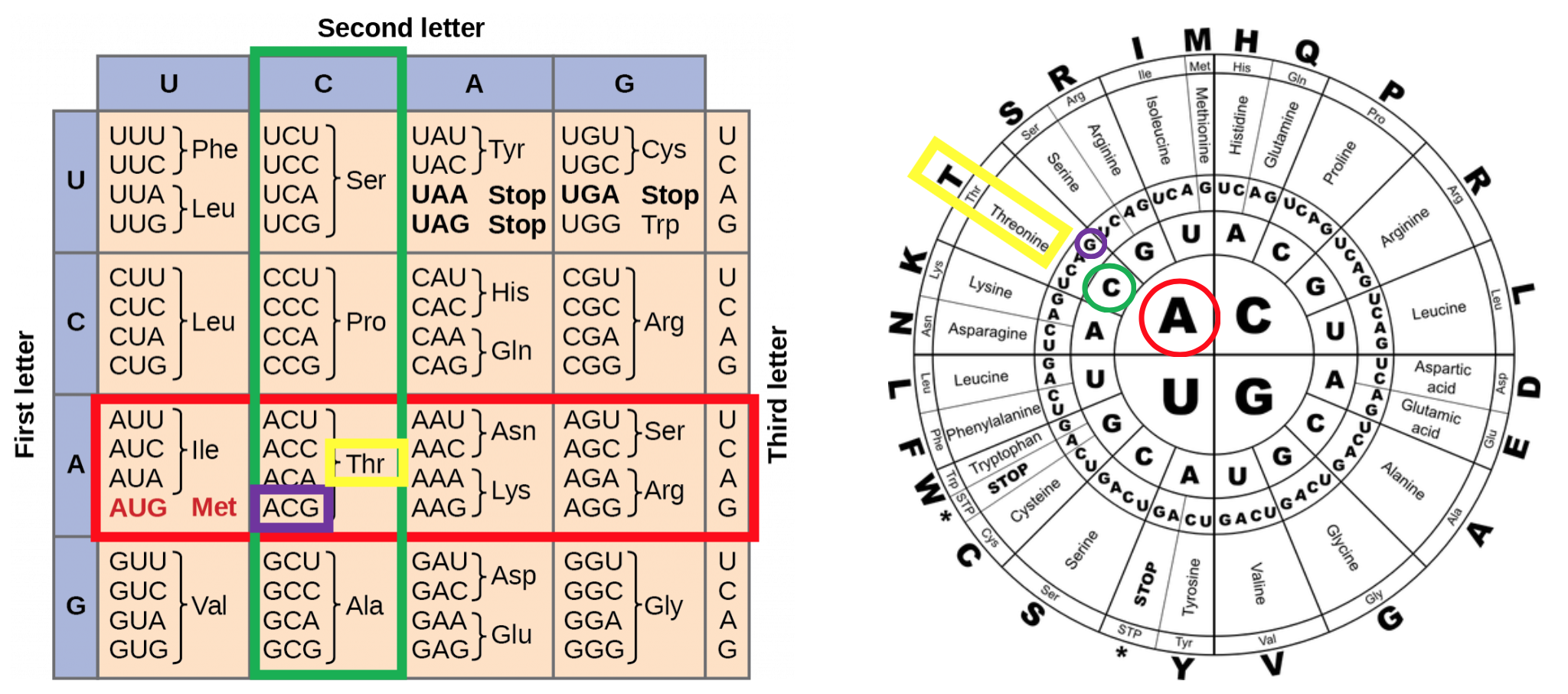
Figure 9 shows two different codon tables: one square, and one round. Both convey the same information. This example shows how to use both tables to determine the amino acid coded for by the DNA sequence TGC. After transcription, the mRNA produced would have the sequence ACG. To use the square table, you begin with the first base (A), which shown in red. Then, you identify the second base (C), which is shown in green. In the box where the first and second bases intersect, you find the third base (G), which is shown in purple. This identifies the amino acid coded for by the mRNA codon ACG as Thr (the three-letter abbreviation for the amino acid threonine). To use the round table, start in the center with the first base (A), circled in red. Move outward to the second base (C), circled in green. Another step outward to the third base (G), which is circled in purple. This again identifies the amino acid coded for by the mRNA codon ACG as Threonine (abbreviated Thr or T).
References
Unless otherwise noted, images on this page are licensed under CC-BY 4.0 by OpenStax.
OpenStax, Biology. OpenStax CNX. May 27, 2016 http://cnx.org/contents/s8Hh0oOc@9.10:FUH9XUkW@6/Translation
